Ansible driven GitOps for OpenShift
Written by Ilkka Tengvall
Task was to automatize software project operations. Software was not designed OpenShift in mind, but was built and operated there. We wanted to have GitOps for the clarity and record of things done. How to achieve such when not being cluster admin at OpenShift (or kubernetes)? How to keep secrets? I’ll explain.
Solution
![]()

![]()
![]()
Ansible k8s module was leashed to control all aspects of OpenShift:
- Projects
- Images
- Build Pipelines
- Secrets
- ConfigMaps
- Routes
- SSL Certificates
- Services
- Backup jobs
- Storage
- Applictions and database
All different sites are version controlled in Git. Applying them to a given environment is super easy:
ansible-playbook -i staging fevermap.yml
This builds the site from scratch, or can ensure the environment matches the definition in git. This can be run from git commit or merge hook for GitOps.
See how it was done in Fevermap.
You can also get some more info about this in Youtube:
Application
In this example we run Fevermap Covid-19 tracking application, which organizations could use to customize to meet their needs. E.g. to track national flu spread. Application and it’s OpenShift setup is described at Fevermap Openshift documentation.

It includes some containerized applications, CI/CD automation, backup task, and a database.
Environments

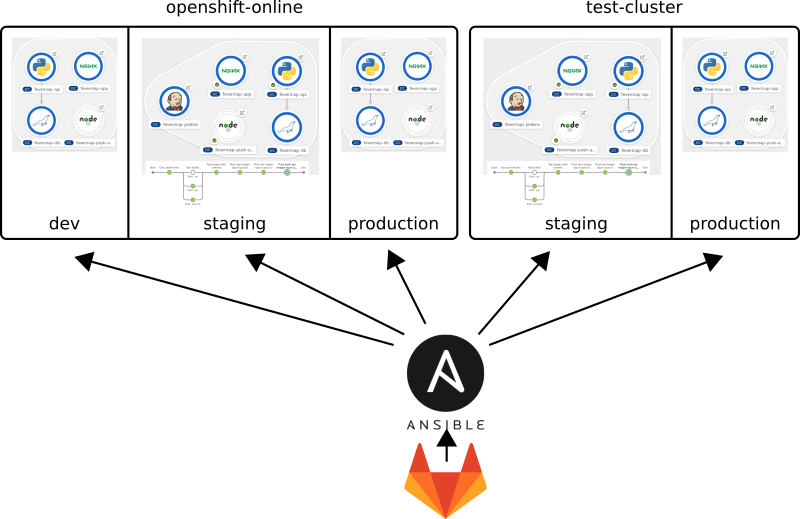
Fevermap runs in OpenShift Online. We have three projects in there:
- Development: Scratch environment, which can be recreated from any given git branch at any time.
- Staging: This follows Fevermap master branch commits, and has pipelines to build software, and do releases for production.
- Production: Follows version tags from git master branch. Staging project’s release pipeline moves tagged software to be run in production. Database backup job saves production database once a day.
In addition I have my own OpenShift cluster called konttikoulu, which I use to test openshift automation. There could be also X amount of production environments if so wished. All it would take is to copy some lines of ansible.
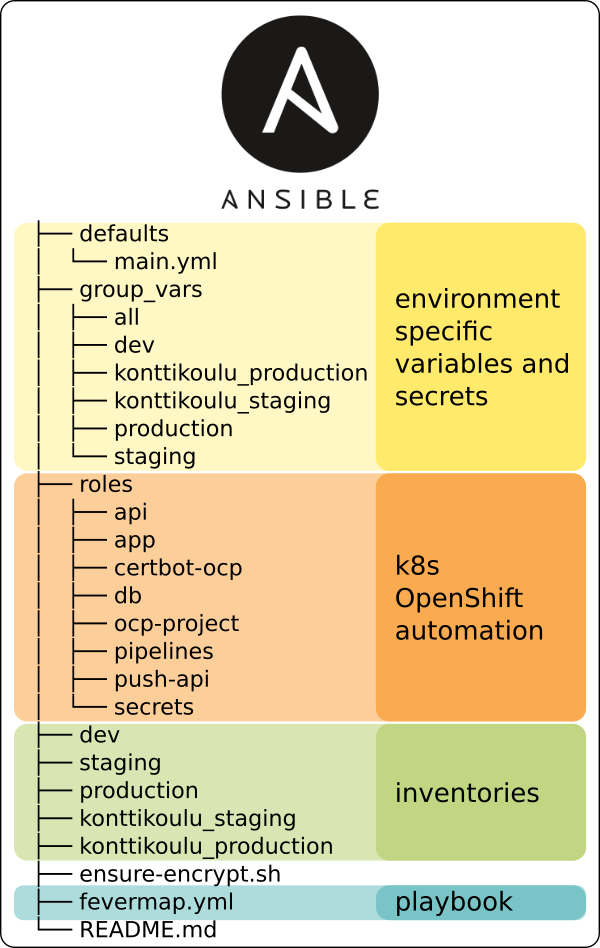
Versioning automation, settings and secrets
Fevermap automation is stored in Fevermap Gitlab. See all the examples from git directly.
Secrets
I get questions how to handle secrets. So let’s start from that. Fevermap is open source project with everything open, but it uses some secrets which we want to control access to. Things like:
- OpenShift access tokens
- Google API keys
- Database password
- Quay container registry access keys
- Webhook tokens
- Mobile push-api (Firebase) access keys
Secrets are stored in ansible vault files, and are unique to site. This way they are versioned within git, but are encrypted so that only those selected ops people who are trusted get the decryption key for git version.
Each site’s secrets may be signed by using different vault credentials, so you can manage who in your organization gets to see and edit which sites secrets.
When ansible playbook is run, it pushes secrets to runtime environment’s etcd to let OpenShift keep them encrypted at site.
Secret file looks like this before encryption to git:
---
vault_api_key: 'xxxxxxxxxxxxxxxxx'
vault_db_user: XXXXXXXXXXXX
vault_db_password: XXXXXXXXXXXXXXX
vault_db_root_password: XXXXXXXXXXXXX
vaut_app_google_analytics_code: 'XX-XXXXXXXXXX-X'
vault_apm_monitoring_js: 'XXXXXXX'
vault_push_api_firebase_account: >-
ewoixxx....xxx...long...key
vault_cb_email: some-email@example.com
I naturally replaced the secrets with X. But you get the idea, just encrypt the minimal amount of things, the secrets, nothing more. Everything else is basic automation and can be visible to all to contribute.
Site variables

All sites are created similar, but details like the following do differ:
- FQDN, web URL
- sizing
- replica count
- storage volumes
- capacity
- autoscaling.
For example, compare staging and production files. They are about the same, but differ in above metioned facts, like:
snipplet from staging
app_build: true
app_fqdn:
- 'staging.fevermap.net'
ws_api_url: "https://{{ api_fqdn }}"
ws_app_url: 'https://staging.fevermap.net'
app_replicas: 1
snipplet from production
app_build: false
app_fqdn:
- 'app.fevermap.net'
- 'app.feberkarta.se'
- 'app.kuumekartta.fi'
ws_api_url: "https://{{ api_fqdn }}"
ws_app_url: 'https://app.fevermap.net'
app_replicas: 2
app_image: 'quay.io/fevermap/fevermap-app'
Most variables are in role defaults, and e.g. above app_image is overrun for production envrironment to come from our Quay.io Fevermap repository instead from the local build ones.
Roles
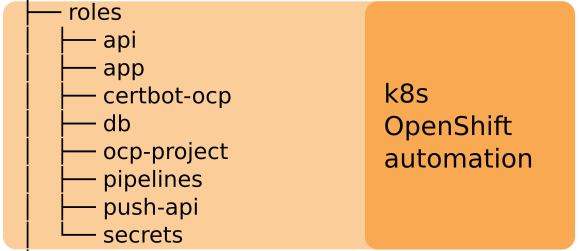
Now we come to common parts for all the environments. We have all the architecture components in different roles. Each role does describe how to run the specified component. So if developer and ops people agree we need to change a bit of how the push API component is setup, it’s enough to modify the push-api role, probably the tasks file.
Look at the roles here, and see how they obey the normal ansible-galaxy created model.
You’ll see they are all written using k8s ansible module. I wanted to keep all the config in ansible task files for them to be in one file, and easy to browse. The other option would be to use yaml templates, but in this case I didn’t like it. I find it easier to maintain this way.
Take a look at e.g. the front-end application component tasks.
Playbook

Finally we are at the playbook of the fevermap. This tells how to create the sites. You can see we do conditional steps in here depending if we want to manage projects or not. In my test env, I’m free to add or delete projects, where as in openhsift-online I don’t have such permissions.
...
tasks:
- include_role:
name: ocp-project
tags: project
when: manage_projects|bool
- name: Do the modules only if project is still present.
block:
- include_role:
name: secrets
tags: secrets
- include_role:
name: db
tags: db
...
Depending on the site or component, I can install or delete the whole application or just update the components of it, like here:
ansible-playbook -i staging fevermap.yml
ansible-playbook -i konttikoulu_production fevermap.yml -t api
ansible-playbook -i dev fevermap.yml -e state=absent
Say, I’d need to update Google API key, I’d update the secret in ansible vault, and I could then just run the secrets role to production.
ansible-vault edit group_vars/production/vault
ansible-playbook -i production fevermap.yml -t secrets
GitOps part
Until this point, this is just version controlling the application automation. To make it gitops, you would create rules which you obey at your project. Flow of the process could be:
- merge master to staging
- change ansible settings in staging branch
- run ansible playbook against staging env, until it’s right
- commit changes to staging
- create pull request from staging to master branch
- your colleague will review the request and accepts it
- change get’s merged to master
- ansible is run from master branch to production
This can be then automated e.g. in GitLab CI tool.
Take a look at our .gitlab-ci file. We don’t have the automation there yet, as I’m not 100% sure about gitlab ci-tool’s open repository’s secret handling.
We could add this code in .gitlab-ci file, it would automate the GitOps:
production_ops:
stage: deploy
only:
refs:
- master
rules:
- if: $CI_COMMIT_REF_NAME =~ /ocp/ansible/
script:
- ansible-playbook -i staging fevermap.yml
- ansible-playbook -i production fevermap.yml
Ansible Tower
I can also execute the same from Ansible Tower GUI.
And watch the results:
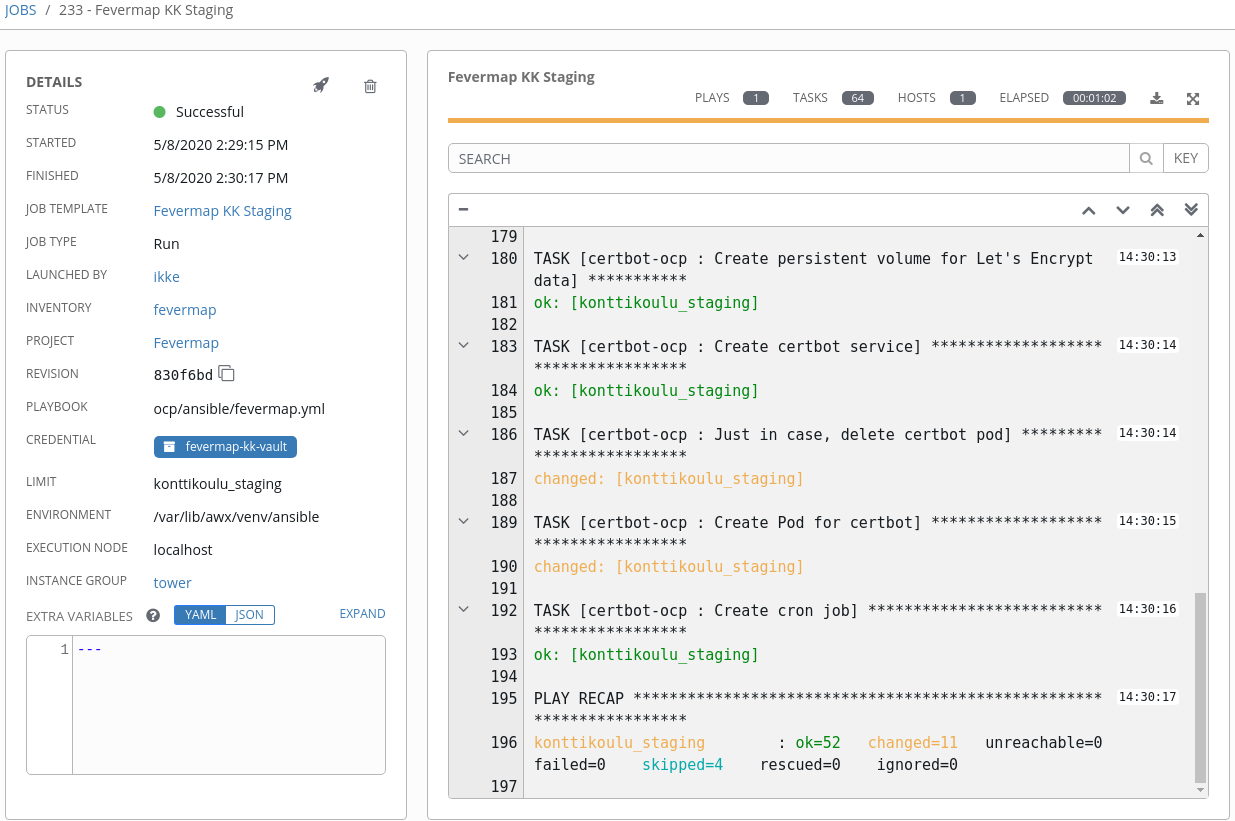
Note how that leaves you with an audit trail of who did it, using which git revision, at what time, and with which parameters? Quite powerful for audit purposes.
But it is topic for another blog how to create role based self service with Ansible Tower. In this case it could set you up with an application developemnt environment in your given OpenShift. Or new production site in new region. I could let GitLab CI/CD call my Tower automations using webhook.
Conclusion
Here we saw how Ansible can help you manage software project in OpenShift. It lets you control it the GitOps way, and handle secrets within your organization. You can let everyone copy/modify/reuse your setup, while still knowing you are safe with your private data.
What a benefit, open source your ops!
There are other ways also, not one fills every purpose. I recommend you to take a look at e.g ArgoCD and Flux. Here is some further reading for you:
BR, Ilkka
I work as an SA at Red Hat Nordics, mainly with speeding things up using automation and hybrid cloud.